と スクレイパーAPICAPTCHA、プロキシ、ブロックされたIPを忘れることができます。この ウェブスクレイピング, リクエストを送信するだけで、 データ 迅速にお届けします。現在、ScraperAPIは数千人のユーザーに採用されています。.
📌 ユーザーによるScraperAPIの長所と短所をまとめた表です:
| ✔️ ハイライト | ❌ 弱点 |
|---|---|
| CAPTCHAの効果的な回避方法 | 不透明な価格設定 |
| プロキシの自動的かつ効率的な管理 | スループットやリクエストに制限がかかることがある |
| 信頼性の高いJavaScriptレンダリング | 大容量には不向き |
| 多言語サポート | 高度なドキュメントは改善される可能性がある |
| 統合の容易さとシンプルなAPI |
ScraperAPIに関するグローバルな意見
ユーザーはScraperAPIを3つの言葉で要約している: 速い, 信頼できる, 効果的.
Trustpilot、G2、Capterraで収集されたすべてのレビューによると、ScraperAPIの平均評価は次のとおりです:
4,6 ⭐⭐⭐⭐⭐
| プラットフォーム | ⭐ 5点満点 |
|---|---|
| トラストパイロット | 4,7 |
| G2 | 4,4 |
| カプタラ | 4,6 |
✔️ よく引用される強み :
- スクレイピングの信頼性と効率性
- 使いやすさと統合性
- 卓越したカスタマー・サポート
- 価格に見合った価値
- 特殊で高度な機能
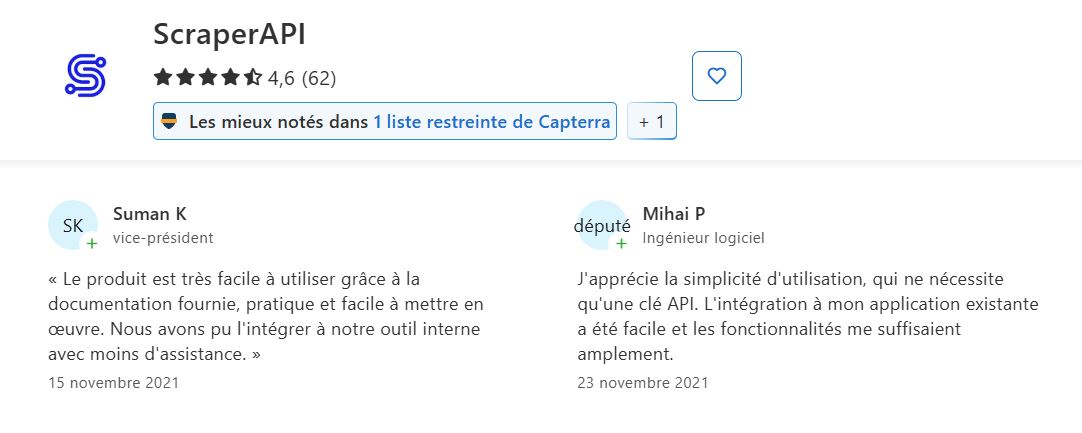
➡️ によると スーマンK と ミハイ・P on Capterra :
“「付属のドキュメントのおかげで、この製品は非常に使いやすく、実用的で導入も簡単です…」”
“「APIキーだけで使えるシンプルさが気に入っています。既存のアプリケーションへの統合も簡単で、機能も十分満足できるものでした。」”
➡️ アキフ Trustpilotで確認する:
“「彼らのカスタマーサービスは素晴らしいです…」”

➡️ ムハンマド・H オンG2 :
“「プロキシ管理、CAPTCHA、ブラウザのレンダリングを処理することでウェブスクレイピングを簡素化し、技術的な問題ではなくデータ抽出に集中できるようにしてくれます。APIは既存のコードにシームレスに統合され、大規模プロジェクトでもその速度は驚くほど高速です。」”

ɴ ユーザーが指摘した課題と弱点:
- 価格設定とコスト意識の明確化 料金システム:ユーザーは料金設定に戸惑うことがある。
- 改善されるべき文書 高度な機能のために。
- 時折発生する問題 フロー制限/クエリーの失敗.
- サポート品質.
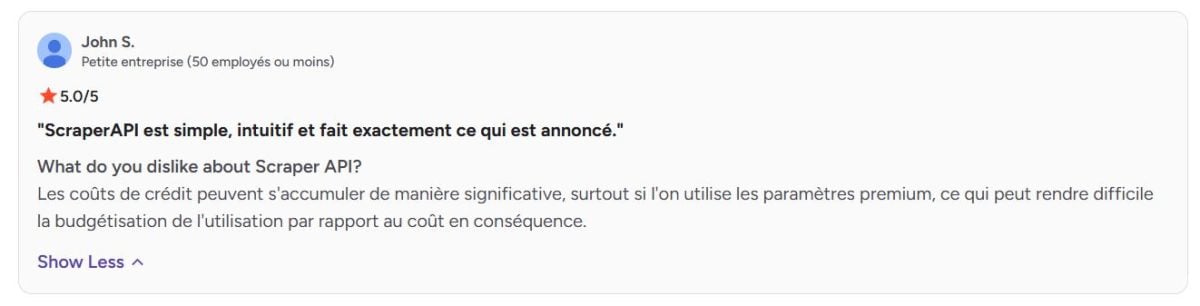
➡️ によると ジョン・SG2について :
“「クレジットコストは、特にプレミアム設定を使用する場合、大幅に積み上がる可能性があり、その結果、使用量とコストの予算編成が困難になる場合があります。」”
ScraperAPIのサービスに対するご意見
ScraperAPIの主なサービスやユーザーの声については、こちらをご覧ください。
1.プロキシの自動ローテーション
ScraperAPIは、リクエストごとに自動的に切り替える大規模なプロキシプールを備えています。.
➡️ によると アディティヤ・プラタップ・シン トラストパイロットで :
“「ScraperAPIは私のウェブスクレイピングプロジェクトに革命をもたらしました。このサービスを見つける前は、常にCAPTCHAやIPアドレスのブロックに悩まされていました。今では、データを取得するのに苦労する代わりに、データの利用に集中できます。プロキシのローテーションはスムーズで、JavaScriptのレンダリングが自動的に処理される点も気に入っています。」”

2.バイパス保護管理
このツールは、複雑なボット対策、ファイアウォール、CAPTCHA、その他のアクセス制限を回避できるため、厳重に保護されたサイトでもスムーズな抽出を保証します。.
➡️ によると アルン K.研究員:
“「Googleは、非営利目的や自己アーカイブ目的であっても、プログラムによるリクエストをブロックすることに成功しており、ScraperAPIはその回避に非常に効果的であることが証明されています。ただし、ScraperAPI経由のリクエストのルーティングは、例えば無料のプロキシサーバー経由の場合よりもはるかに遅くなります。」”

3.JavaScriptレンダリング
統合されたヘッドレス・ブラウザのおかげで、ScraperAPIは、コンテンツがJavaScriptを介して読み込まれる動的なサイトをスクレイピングすることができる。
➡️ ファスト・テック トラストパイロットで :
“「ScraperAPIは、当社のウェブスクレイピングプロセスを大幅に改善しました。このAPIは統合が簡単で、IPアドレスのローテーションやプロキシ管理など、ほとんどの面倒な作業を代行してくれるため、貴重な時間を節約できます。キャプチャの自動処理は大きな利点であり、データ収集を大幅に簡素化してくれます。」”

4.クエリのカスタマイズ
HTTPリクエストは、ヘッダー、クッキー、ユーザーエージェントを変更することでカスタマイズできる。
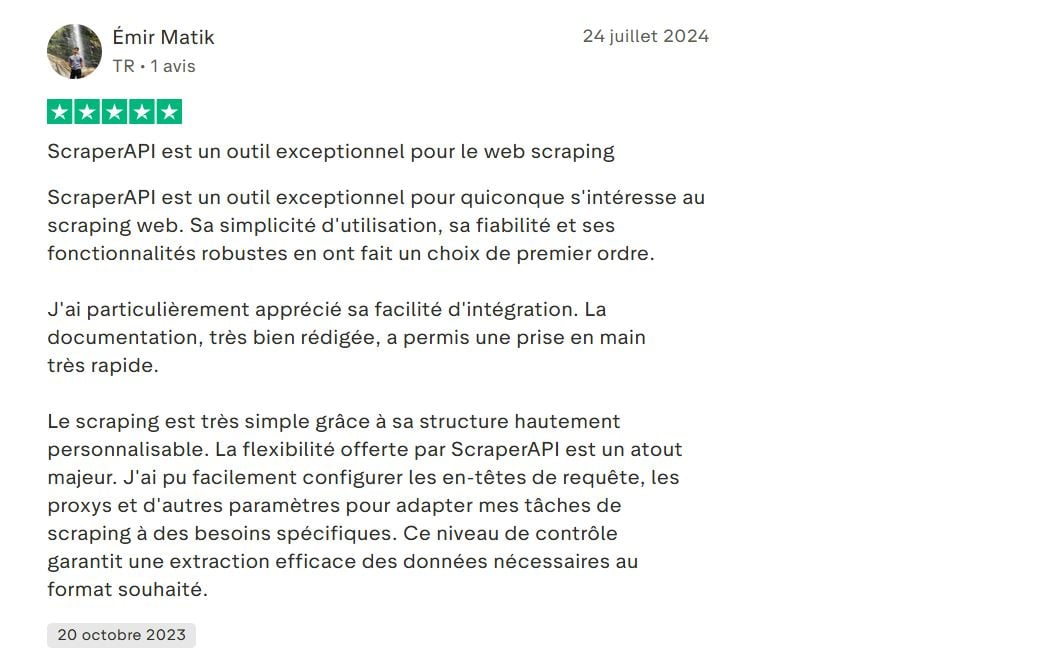
➡️ こちらが意見です エミール・マティック トラストパイロットで :
“「…スクラッピングは非常にシンプルで、高度にカスタマイズ可能な構造となっています。ScraperAPIが提供する柔軟性は大きな強みです。リクエストヘッダー、プロキシ、その他の設定を簡単に構成でき、特定のスクラッピングタスクを特定のニーズに合わせて調整することができました…」”
5.プロキシのジオロケーション
ScraperAPIでは、プロキシの地理的な位置(国別)を選択することができます。これは、地域限定のデータを取得したり、特定の地域に固有の結果をテストしたりするのに便利です。.
➡️ メリ・クルス トラストパイロットで :
“「…さらに、JavaScriptのレンダリングとIPによる位置情報検出の処理も非常に有用でした…」”

6.ダッシュボードと統計
包括的なダッシュボードにより、使用状況、リクエスト数、成功率、残りのクレジットを追跡できます。これにより、スクレイピングの管理と最適化が容易になります。.
➡️ によると タフミーム・S オンG2 :
“「ユーザーインターフェースはかなり良く、データ転送機能はとても便利です。ダッシュボードはプロセスの概要を把握するのに非常に役立ちます。私はこのツールをウェブスクレイピングに使用しています。研究に使用するウェブページのコンテンツを取得するのに役立つからです。」”

7.統合と多言語サポート
ScraperAPIは、複数の言語(Python、Node.js、PHP、Javaなど)と簡単に統合できるシンプルなREST APIを提供しており、さまざまな環境での導入が容易です。
➡️ こう書いてある。 デニ・H. オンG2 :
“「APIスクレイパーの経験は、おそらくウェブスクレイピングに精通した開発者であり、Python(BeautifulSoupとSelenium)、JavaScript(PuppeteerまたはCheerio)、Node.js(DemandとCheerio)を含む様々なスクレイピング技術に関する知識を有しているでしょう…」”

8.データのための高度な機能
- 非同期スクレイピング・サービス : 非常に大規模なスクレイピングのニーズに対応するため、何百万ものリクエストを非同期で送信することを可能にします。.
- 構造化データ データ処理を容易にするため、JSONまたはCSVで直接出力。
- データパイプライン データ検索:継続的なデータ検索をコーディングなしで完全自動化。
➡️ によると アラム M.G2 のデジタル・マーケティング・マネージャー:
“「…この情報を自動的にExcelまたはCSV形式で保存することができます…」”

スクレイパーAPI : 代替品
ScraperAPIは、ウェブスクレイピング市場で唯一のプレイヤーではありません。いくつかの代替手段は、そのアプローチ、価格、機能によって際立っています:
- ブライトデータ 最も包括的なウェブデータ・プラットフォーム。
- スクレイピング・ビー ScraperAPIの主な競合相手である。
- オクトパース コードを使わない視覚的アプローチ。
- アピファイ スクラッパー開発プラットフォーム。
| ツール | 📌 特集 | ユーザーレビュー | 平均格付け |
|---|---|---|---|
| スクレイパーAPI | プロキシの自動ローテーション、JavaScriptレンダリング、カスタマイズ | 信頼性が高く使いやすいが、料金体系が分かりにくい場合がある | 4,6 |
| ブライトデータ | プレミアムプロキシと高度なデータパイプラインを備えた最も包括的なプラットフォーム | 非常に強力で柔軟だが、使いこなすのは複雑 | 4,6 |
| スクレイピング・ビー | JSレンダリングとプロキシローテーションによるシンプルなAPI | 導入が容易でコストパフォーマンスに優れるが、高度なオプションが少ない | 4,9 |
| オクトパース | コードを使わないビジュアル・スクレイピング、プログラミング不要のアプローチ | 技術者でないユーザーには理想的だが、大容量に限られる | 4,4 |
| アピファイ | カスタムスクレーパー開発用プラットフォーム | 柔軟性が高くカスタマイズ可能だが、高度な専門知識が必要 | 4,8 |
ScraperAPIは、人気のあるバランスの取れたソリューションです。しかし、いくつかの代替案は、異なるプロファイルに適応した興味深いソリューションを提供しています、 ブライトデータ のままである。 ウェブデータプラットフォーム 市場で最も完全で強力なものである。
ブライト・データの格付けが少し低いのは、そのためである。 プレミアム・ポジショニング これはすべてのユーザーに適しているわけではない。
➡️ ニクラス とCapterraは言う:
“「Bright Dataはより高価なサービスですが、同カテゴリーで最高のものと言えます。」”

よくある質問
ScraperAPIは無料ですか?
ScraperAPIは無料ではありませんが、以下のサービスを提供しています。 無料体験 限られている。
ScraperAPIの価格はいくらですか?
ScraperAPIの価格は一般的に以下の通りです。 49$ と 475$ 月あたり。
ScraperAPIはどのように機能するのですか?
技術的には、ScraperAPIは 中間 アプリケーションとスクレイピング対象のウェブサイト間の通信を管理します。プロキシのローテーション、IP管理、JavaScriptのレンダリング、保護機能の回避を自動的に処理します。このツールを使用すると、 ブロックせずにデータを復元.
PythonでScraperAPIを使うには?
Pythonとの統合は、よく文書化されたREST APIのおかげで簡単です。ScraperAPIのAPIアドレスに、APIキーとターゲットURLを指定してHTTPリクエストを送信するだけです。.
1. APIキーとターゲットURLを使用してScraperAPIのURLを設定する
輸入リクエスト
url = "http://api.scraperapi.com"
params = {
'api_key': 'YOUR_API_CLE'、
'url': 'https://exemple.com'
}2.リクエストを送信する
response = requests.get(url, params=params)3.検索されたページの内容を表示する
print(response.text)ScraperAPIはCAPTCHAを回避できますか?
はい. ScraperAPIの強みのひとつは、CAPTCHAやその他のボット対策システムを自動的に回避できることです。.
🔚 まとめると、ScraperAPIはオンラインデータ収集を自動化する高性能なソリューションとして確立しています。しかし、より包括的なサービスを求めるなら、, Bright Dataは理想的な選択肢です.
コメント欄で質問を投稿したり、ご自身の経験を共有したりしてください!





