AWS полностью упрощает веб-парсинг. Вам больше не нужно заниматься управлением серверами или скриптами, которые выходят из строя.
Все автоматизируется и вы сможете без проблем обрабатывать большие объемы данных.

Какова роль AWS в веб-парсинге?
в скраппинг позволяет автоматически извлекать данные на веб-сайтах для их анализа или повторного использования.
⚠ Но будьте осторожны, это не всегда просто. Управление миллионами страниц, предотвращение блокировок и обеспечение надежности могут быстро стать настоящей головной болью.
✅ Именно здесь’AWS (Amazon Web Services) вмешивается. Эта платформа облако Amazon упрощает веб-парсинг, автоматизация управления серверами. Преодолевая технические проблемы, она также гарантирует стабильную и безопасную работу даже при обработке огромных объемов данных.
Вот несколько моментов, которые подтверждают, что AWS является идеальным решением для веб-парсинга:
- 🔥 Масштабируемость : платформа может автоматически наращивать мощность для обработки миллионов запросов без перебоев.
- 🔥 Надежность : управляемые услуги AWS сводят к минимуму риск сбоев и обеспечивают непрерывную работу.
- 🔥 Экономическая эффективность : благодаря модели оплаты по факту использования (pay-as-you-go) вы платите только за то, что потребляете.
- 🔥 Безопасность : AWS внедряет меры безопасности для защиты данных.
Какие услуги AWS подходят для этого?
AWS предлагает широкий спектр услуг, адаптированных к различным потребностям веб-парсинга.
- Расчет
➡ AWS Lambda: для небольших задач.
➡ Amazon EC2: для длительных или ресурсоемких процессов.

- Хранилище
➡ Amazon S3: для безопасного хранения необработанных данных, файлов или результатов скрапинга.
➡ Amazon DynamoDB: для структурированных данных, требующих быстрой чтения/записи.
- Оркестровка
➡ AWS Step Functions: для управления сложными рабочими процессами.
- Другие услуги
➡ Amazon SQS: для управления очередями запросов и организации обработки данных.
➡ AWS IAM: для управления доступом.
Как создать бессерверный скрейпер с помощью AWS Lambda?
С AWS Lambda, вам не нужно управлять сервером. AWS управляет всей инфраструктурой (масштабируемость, доступность, обслуживание). Вам остается только предоставить свой код и конфигурацию.
Следуйте инструкциям в следующем учебном пособии, чтобы создать бессерверный скрейпер с AWS Lambda.
1. Базовая архитектура бессерверного скрепера
Для начала необходимо представить, как различные службы AWS будут взаимодействовать друг с другом.
- Выбор спускового механизма
Это элемент, который определяет, когда ваш код должен выполняться. У вас есть CloudWatch а также EventBridge.
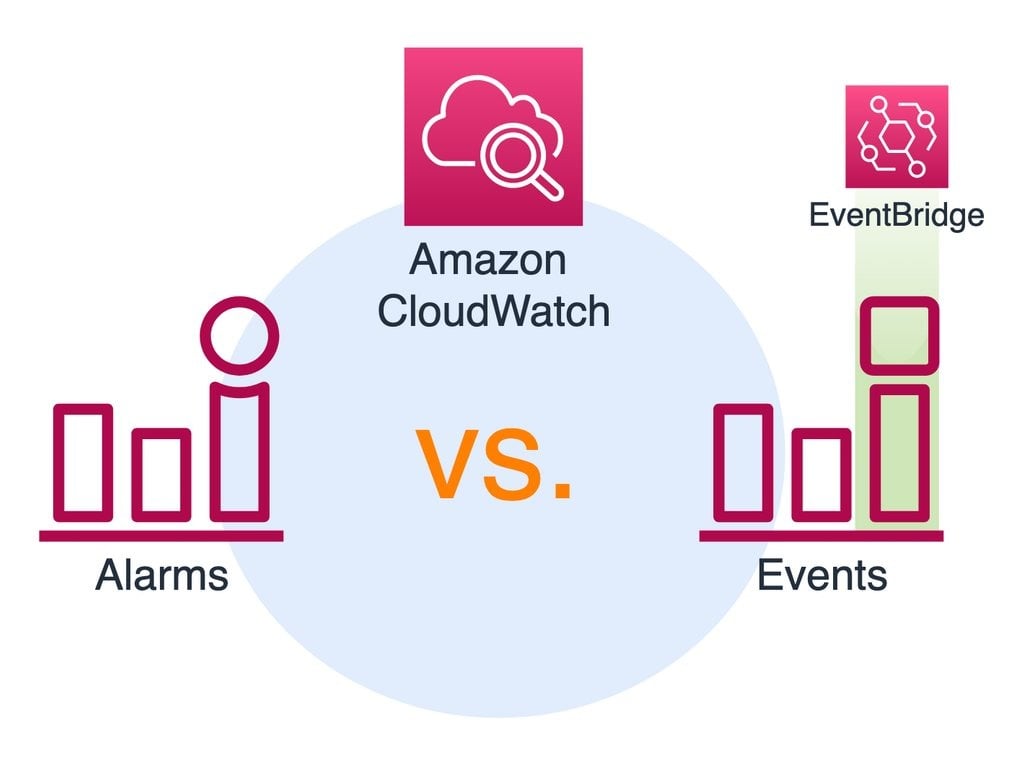
- Выбрать вычислительную мощность
Это место, где ваш код выполняется в облаке. лямбда для коротких и эпизодических задач, EC2/Fargate если работа длительная или тяжелая.
- Выбор хранилища
Это хранилище, в которое ваш скрейпер сохраняет результаты. S3 для файлов JSON/CSV/сырых, DynamoDB если вам нужен быстрый и структурированный доступ.
✅ В целом, триггер активирует Lambda, Lambda выполняет скрейпинг, и данные хранятся в S3.
2. Подготовка окружающей среды
Перед началом кодирования необходимо предоставить AWS разрешения и место для хранения данных.
- Создать роль IAM (разрешения)
- Перейдите в консоль AWS > IAM > Роли.
- Создайте роль, предназначенную для Lambda.
- Предоставьте ему два основных разрешения:
AWSLambdaBasicExecutionRoleдля отправки журналов в CloudWatch и разрешение S3 для записи файлов в ваш букет.
- Создание корзины S3 (хранение результатов)
- Перейдите в консоль AWS > S3.
- Создайте корзину.
- Оставьте параметры безопасности включенными.
✅ С этим вы дали Lambda право записывать в S3 и получили место для хранения ваших данных.
3. Код Python для AWS Lambda
Теперь вы можете написать небольшой скребковый алгоритм на Python, с помощью простой библиотеки, такой как Requests. Этот скрипт загрузит страницу и сохранит результат в S3.
- Пример простого кода (с запросами):
import json import boto3 import requests import os from datetime import datetime s3_client = boto3.client('s3') def lambda_handler(event, context): # URL для скрапирования (здесь простой пример) url = "https://example.com" response = requests.get(url) # Проверка статуса if response.status_code == 200: # Имя файла (с временной меткой для предотвращения коллизий)
filename = f"scraping_{datetime.utcnow().isoformat()}.html" # Отправка в S3 s3_client.put_object( Bucket=os.environ['BUCKET_NAME'], # определить в переменных среды Lambda
Key=filename, Body=response.text, ContentType="text/html" ) return { 'statusCode': 200, 'body': json.dumps(f"Страница сохранена в {filename}")
} else: return { 'statusCode': response.status_code, 'body': json.dumps("Ошибка при скрапинге") }➡ Запросы позволяет получить содержимое веб-страницы.
➡ boto3 является официальной библиотекой для связи с AWS
- Управление зависимостями (запросы или Scrapy)
Lambda по умолчанию не предоставляет requests или Scrapy, поэтому у вас есть два варианта:
👉 Создать ZIP-архив
- Создайте папку на своем компьютере:
mkdir package && cd package pip install requests -t .- Добавьте свой файл
lambda_function.pyв этом деле. - Сжимайте все в
.zipи загрузите его в Lambda.
👉 Использование Lambda Layers
- Вы создаете слой Lambda, который содержит Requests (или Scrapy, если вам нужен более продвинутый скрейпинг).
- Вы прикрепляете этот слой к своей функции Lambda.
Преимущество : это более чисто, если вы повторно используете одни и те же зависимости в нескольких функциях.
4. Развертывание и тестирование
Осталось разместить ваш код в сети и проверить, что он работает.
- Загрузить код в Lambda
- Подключитесь к консоли AWS и перейдите в службу Lambda.
- Нажмите на Создать функциюзатем выберите Автор с нуля.
- Дайте название своей функции (пример:
скребок-лямбда) и выберите среда выполнения Python 3.12 (или версия, которую вы используете). - Свяжите созданную вами роль IAM с разрешениями S3 + CloudWatch.
- В Закодировановыбирать Загрузить из, тогда
.zip файли импортируйте ваш файлlambda_package.zip(тот, который содержит ваш код и зависимости, такие какЗапросы). - Добавьте переменную среды:
BUCKET_NAME= название вашего S3-бакета. - Нажмите на Сохранить для сохранения вашей должности.
- Проверить функцию
- В вашей функции Lambda нажмите Тест.
- Создайте новое тестовое событие с небольшим JSON, например:
{ "url": "https://example.com" }- Нажмите на Сохранитьдалее Тест для выполнения функции.
- В Журналы, проверьте статус: если все прошло успешно, вы должны увидеть код 200.
- Перейдите в свой S3-бакет: вы должны увидеть файл
scraping_xxxx.html.
Какие существуют решения для веб-парсинга в больших масштабах?
Для сбора миллионов страниц требуется надежная инфраструктура. AWS предлагает несколько инструментов, которые позволяют, в частности, наращивать мощность.
1. Использование Scrapy и AWS Fargate/EC2

Scrapy идеально подходит для сложных проектов. Он позволяет вам’написать свой код для скрапинга. Но по умолчанию ваш скрейпер работает на вашем компьютере, что быстро ограничивает его возможности.
AWS Fargate позволяет запустить ваш скрейпер Scrapy в контейнеры Docker без необходимости управлять сервером. Это необходимо для автоматического масштабирования.
Amazon EC2 также является альтернативой, если вы хотите иметь больше контроля над своей средой.
✅ В целом, чтобы контейнеризировать скрейпер Scrapy:
- ✔ Вы создаете свой скрейпер Scrapy.
- ✔ Вы помещаете его в контейнер Docker.
- ✔ Вы развертываете этот контейнер с помощью Fargate, чтобы он автоматически запускался в большом масштабе.
2. Распределенная архитектура скрапинга
Вы можете использовать Amazon SQS (Simple Queue Service). Он служит для управления очередью URL-адресов, которые необходимо сканировать. Достаточно просто поместить все URL-адреса в SQS, а затем несколько функций Lambda или несколько контейнеров (на EC2 или Fargate). получают эти URL-адреса параллельно для запуска скрапинга.
Это позволит вам распределять работу и одновременно продвигаясь вперед.
3. Управление прокси-серверами и заблокированными запросами
Следует знать, что многие сайты блокируют скрейперы, обнаруживая слишком много запросов или фильтруя определенные IP-адреса.
Решения тогда следующие:
- La ротация IP-адресов через AWS или специализированные сервисы.
- Использование сторонние прокси-серверы в качестве Яркие данные Где ScrapingBee которые автоматически управляют вращением и антиблокировкой.

Каковы решения типичных проблем веб-парсинга с помощью AMS?
При веб-парсинге всегда возникают препятствия: сетевые ошибки, блокировки, непредвиденные расходы и т. д. Преимущество заключается в том, что AWS уже предлагает инструменты для быстрой диагностики и устранения этих проблем.
Анализ журналов с помощью Amazon CloudWatch
Когда функция Lambda или экземпляр EC2 выходит из строя, без видимости сложно определить, откуда происходит ошибка.
✅ Решение с Amazon CloudWatch : все журналы централизованы и доступны для просмотра. В них можно найти такие частые ошибки, как:
- Timeouts (запрос занял слишком много времени).
- Ошибки 403 Forbidden (сайт блокирует ваш скрейпер).
- Ошибки 429 Too Many Requests (отправлено слишком много запросов).
- Недостаток памяти или отсутствующие зависимости в Lambda.
💡 Настроить оповещения CloudWatch чтобы получать автоматическое уведомление, когда ошибка повторяется слишком часто.
Обработка ошибок запросов
Скрейпер может полностью зависнуть, если не пройдет один запрос.
✅ Использование управления ошибками в Python с помощью try...except. Это предотвращает резкое завершение работы программы.
✅ Стратегии повторных попыток (повторные попытки):
- Повторите попытку через короткий промежуток времени, затем постепенно увеличивайте время ожидания (экспоненциальное отставание).
- Переключаться между несколькими прокси-серверами, если IP-адрес заблокирован.
- Настройте частоту запросов, чтобы остаться незамеченным.
Контроль затрат
Плохо оптимизированный скрейпер может генерировать тысячи вызовов Lambda или запускать большой экземпляр EC2 без необходимости. Это приводит к гораздо более высоким затратам, чем ожидалось.
✅ Решение с AWS Billing : отслеживать потребление каждого сервиса (Lambda, EC2, S3, прокси).
✅ Советы по оптимизации :
- Для Lambda: уменьшить объем памяти или ограничить время выполнения.
- Для EC2: выбирайте подходящие инстансы или используйте Spot Instances (более дешевые, но могут быть прерваны в любой момент).
- Активируйте бюджетные оповещения AWS, чтобы получать уведомления до превышения порогового значения.
Часто задаваемые вопросы
Является ли веб-парсинг с помощью AWS законным?
Это зависит от обстоятельств.
La Законность веб-скреппинга зависит от страны, собираемых данных и того, как вы их используете. Некоторые сайты также запрещают скрапинг в своих условиях.
Какой подход к веб-парсингу лучше всего подходит для AWS?
Все зависит от вашего проекта:
- AWS Lambda : для небольших быстрых скребков.
- EC2 : для более сложных проектов.
- Фаргейт : для распределенного скрапинга.
Могу ли я использовать Selenium на AWS Lambda для веб-парсинга?
👉 Да, но это сложнее.
Селен или другие бесглавные браузеры такие как Puppeteer, являются необходимыми для скрепинг в Javascript. Однако их конфигурация на Lambda требует оптимизации (размер пакета, управление зависимостями).
Как я могу избежать блокировки веб-сайта на AWS?
Сайты могут обнаруживать скрейперы и блокировать запросы. Вот несколько распространенных тактик, позволяющих снизить риски:
- ✔ Регулярно меняйте User-Agent.
- ✔ Добавить случайные задержки между запросами.
- ✔ Использование ротационных прокси.
- ✔ Избегайте отправки слишком большого количества запросов одновременно с одного и того же IP-адреса.
Как интегрировать собранные данные в базу данных?
После сбора данных вы можете ввести их в реляционную базу данных, например Amazon RDS (MySQL, PostgreSQL и т. д.).
Надлежащая практика заключается в следующем очищать и структурировать данные перед вставкой, а затем’автоматизировать интеграцию с помощью скрипта Python или конвейера. Это гарантирует чистую и готовую к использованию базу данных.
👌 Короче говоря, сочетая мощь’AWS и передовые методы скрапинга, вы можете эффективно и безопасно извлекать данные. Не стесняйтесь делиться своим опытом в комментариях!





