Bagaimana jika Anda bisa mengirimkan robot kecil untuk menjelajahi web atas nama Anda? Itulah tepatnya yang dapat dilakukan oleh sebuah bot. pengikisan web : mengumpulkan data secara otomatis yang menarik bagi Anda.

Persyaratan untuk membuat bot scraping web
Untuk memulainya, penting untuk memilih bahasa pemrograman yang tepat untuk membuat bot pengikis web.
- Python : Ini adalah bahasa pemrograman paling populer untuk web scraping. Mudah digunakan dan menawarkan banyak perpustakaan.
- Node.js Ini sangat ideal untuk mengelola tugas-tugas asinkron dan oleh karena itu sangat efektif untuk menggores situs dinamis.
- Bahasa lain Untuk proyek-proyek tertentu, Anda juga dapat memilih untuk scraping web dengan PHP.
Setelah Anda memilih bahasa, Anda harus memilih bahasa yang tepat perpustakaan dan kerangka kerja untuk menyederhanakan tugas pengikisan Anda. Berikut ini yang paling efektif:
➡ Untuk Python:
- Permintaan : memungkinkan pengiriman permintaan HTTP.
- BeautifulSoup parser: berguna untuk mengurai dan mengekstrak data dari HTML.
- Scrapy kerangka kerja yang lengkap untuk proyek pengikisan yang lebih kompleks.
➡ Untuk Node.js :
- Axios Di mana Mengambil untuk mengirim permintaan HTTP.
- Cheerio mirip dengan BeautifulSoup, sangat efektif untuk menjelajah dan memanipulasi DOM.
- Dalang Di mana Penulis naskah penting untuk mengikis situs dinamis yang menggunakan banyak JavaScript.
Tutorial untuk membuat bot scraping web
Membuat bot pengikis web Mungkin terlihat rumit. Tapi jangan khawatir! Dengan mengikuti langkah-langkah ini, Anda akan memiliki skrip yang berfungsi dengan cepat.
⚠ Pastikan Anda telah menginstal Python beserta perpustakaan yang diperlukan.
Langkah 1: Menganalisis situs target
Sebelum melakukan pengkodean, Anda harus mengetahui di mana letak data. Untuk melakukan ini:
-
- Buka situs di browser Anda.
- Klik kanan dan pilih “Periksa” pada elemen yang Anda minati.
- Identifikasi tag HTML, kelas atau ID yang berisi data yang akan diekstrak (Contoh :
.product,.title,.price). - Tes Pemilih CSS di konsol (Contoh: jika judul produk ada di
<h2 class="title">gunakan pemilih ini dalam kode Anda).
Langkah 2: Mengirim permintaan HTTP
Bot Anda akan berperilaku seperti peramban: bot mengirimkan permintaan HTTP ke server situs dan server mengembalikan kode HTML.
Permintaan pemasangan pip #
permintaan impor
url = "https://exemple.com/produits"
header = {"User-Agent": "Mozilla/5.0"}
resp = requests.get(url, headers = headers, timeout = 15)
resp.raise_for_status() kesalahan # jika kode != 200
html = resp.text
print(html[:500]) pratinjau #Langkah 3: Mengurai konten HTML
Sekarang setelah Anda mengambil halaman, Anda perlu mengubahnya menjadi objek yang dapat dimanipulasi.
Itu adalah peran dari BeautifulSoup.
# pip install beautifulsoup4
dari bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
produk = sup.select(".product")
print(f "Produk ditemukan : {len(produk)}")
for p in products[:3]:
judul = p.select_one("h2.judul").get_text(strip=True)
harga = p.select_one(".harga").get_text(strip=True)
link = p.select_one("a")["href"]
print({"judul": judul, "harga": harga, "tautan": tautan})Langkah 4: Ekstrak data
Ini adalah tahap yang paling menarik: mencari informasi yang tepat seperti judul, harga, dan tautan.
from urllib.parse import urljoin
base_url = "https://exemple.com"
data = []
for p in sup.select(".product"):
judul = p.select_one("h2.title").get_text(strip=True)
prix_txt = p.select_one(".price").get_text(strip=True)
lien_rel = p.select_one("a")["href"]
lien_abs = urljoin(base_url, lien_rel)
Harga normalisasi #
harga = float(harga_txt.replace("€","").replace(",",".").strip())
data.append({"judul": judul, "harga": harga, "url": link_abs})
print(data[:5])Langkah 5: Mencadangkan data
Jika Anda tidak ingin kehilangan hasil, Anda dapat menyimpannya di folder CSV Di mana JSON.
impor csv, json, pathlib
pathlib.Path("export").mkdir(exist_ok=True)
# CSV
with open("export/products.csv", "w", newline="", encoding="utf-8") as f:
fields = ["judul", "harga", "url"]
penulis = csv.DictWriter(f, nama_field = fields, pembatas = ";")
penulis.writeheader()
penulis.tulisbagian(data)
JSON #
dengan open("export/products.json", "w", encoding="utf-8") sebagai f:
json.dump(data, f, ensure_ascii = False, indent = 2)
print("Ekspor selesai!")Bagaimana Anda menyiasati tindakan perlindungan pengikisan web?
Penting untuk diketahui bahwa situs-situs tersebut menerapkan sejumlah mekanisme untuk melindungi data mereka. Memahami perlindungan ini sangat penting untuk melakukan penggosokan yang efisien dan bertanggung jawab.
- robots.txt
📌File robots.txt menunjukkan halaman mana yang dapat atau tidak dapat dikunjungi oleh bot.
✅ Selalu periksa file ini sebelum melakukan scraping pada sebuah situs. Mematuhi file ini akan membantu Anda menghindari tindakan yang tidak sah dan masalah hukum.
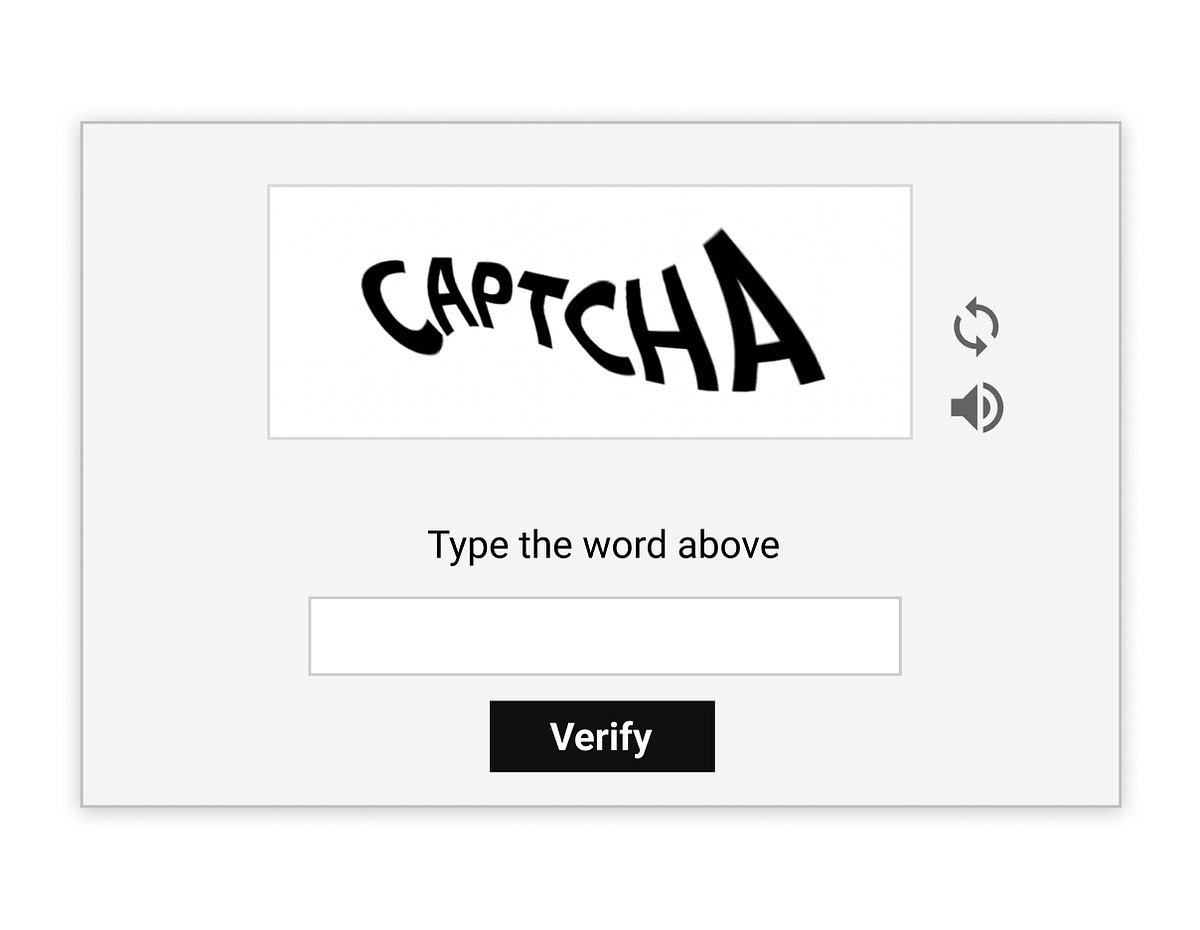
- Captcha
📌 Mereka digunakan untuk memverifikasi bahwa pengguna adalah manusia.
✅ Untuk mengatasinya, gunakan perpustakaan otomatisasi untuk mensimulasikan browser asli atau layanan pihak ketiga yang khusus menangani captcha.
- Pemblokiran berdasarkan alamat IP
📌 Beberapa situs mendeteksi sejumlah besar permintaan yang berasal dari alamat IP yang sama dan memblokir akses.
✅ Oleh karena itu, disarankan untuk menggunakan proxy atau VPN untuk secara teratur mengubah alamat IP.
- Pemblokiran oleh agen pengguna
📌 Situs dapat menolak permintaan dari bot yang diidentifikasi oleh Agen-Pengguna yang mencurigakan.
✅ Triknya adalah mendefinisikan User-Agent yang realistis dalam permintaan HTTP Anda untuk mensimulasikan browser konvensional.
- Situs web JavaScript
📌 Beberapa halaman memuat konten mereka melalui JavaScript, yang mencegah permintaan HTTP sederhana untuk mengambil data.
✅ Untuk menyiasatinya, Anda bisa menggunakan alat seperti Selenium, Playwright, atau Puppeteer.
FAQ
Apa perbedaan antara bot scraping web dan perayap web?
| Pengikisan web | Perayap web |
|---|---|
| Berfokus pada data spesifik judul, harga, tautan produk, dll. Bot membaca HTML, mengidentifikasi elemen-elemen yang relevan dan mengekstraknya untuk digunakan lebih lanjut (analisis, penyimpanan, ekspor, dll.). |
Ini adalah program yang secara otomatis menjelajahi halaman web dengan mengikuti tautan untuk temukan konten. Tujuannya utama adalah menjelajahi web untuk memetakan dan mengindeks informasi, tetapi tidak selalu untuk mengekstrak data yang spesifik. |
Apakah web scraping legal?
Itu legalitas web scraping Bervariasi tergantung pada situs web, jenis data yang dikumpulkan, dan penggunaan data tersebut.
Jenis data apa saja yang bisa diekstrak dengan bot scraping web?
Dengan bot pengikis web, Anda dapat mengumpulkan file :
- 🔥 Des judul dan deskripsi produk.
- 🔥 Des harga dan promosi.
- 🔥 Des tautan internal atau eksternal.
- 🔥 Des Ulasan dan penilaian pengguna.
- 🔥 Des detail kontak.
- 🔥 Des konten tekstual atau gambar halaman web.
Bagaimana situs web dapat mendeteksi bot scraping saya?
Situs sering kali mendeteksi bot melalui perilaku abnormal seperti :
- ❌ yang kecepatan permintaan terlalu tinggi atau biasa
- ❌ l’agen pengguna non-standar
- ❌ l’tidak ada pemuatan sumber daya JavaScript diperlukan
- ❌ yang penjelajahan bebas cookiedll.
Apa saja tantangan umum yang dihadapi saat membuat bot web scraping?
Membuat bot yang efektif tidak selalu mudah. Di antara tantangan yang sering muncul, antara lain:
- 🎯 yang struktur HTML yang tidak konsisten.
- 🎯 yang data tidak terstruktur.
- 🎯 yang waktu pemuatan yang lambat halaman.
Apakah ada layanan web scraping atau API?
Ya ! Ada layanan yang menyederhanakan scraping dan mengelola aspek-aspek seperti proksi, captcha, dan situs dinamis.
Anda juga dapat menggunakan API pengikisan web untuk mengakses data terstruktur. Data Cerah adalah salah satu solusi yang paling lengkap.
💬 Singkatnya, web scraping membuka banyak kemungkinan untuk memanfaatkan data dari web. Membuat bot web scraping memungkinkan Anda mengotomatisasi pengumpulan data.




