Et si vous pouviez envoyer un petit robot parcourir le web à votre place ? C’est exactement ce que permet un bot de web scraping : collecter automatiquement les données qui vous intéressent.

Prérequis pour créer un bot de web scraping
Pour commencer, il est important de choisir le bon langage de programmation pour créer un bot de web scraping.
- Python : c’est le langage le plus populaire pour le web scraping. Il est facile à utiliser et propose de nombreuses bibliothèques.
- Node.js : il est idéal pour gérer des tâches asynchrones et donc très efficace pour le scraping de sites dynamiques.
- Autres langages : pour certains projets, vous pouvez également opter pour le web scraping avec PHP.
Une fois le langage choisi, il vous faut sélectionner les bonnes bibliothèques et frameworks pour simplifier vos tâches de scraping. Voici les plus efficaces :
➡ Pour Python :
- Requests : permet d’envoyer des requêtes HTTP.
- BeautifulSoup : pratique pour parser et extraire des données du HTML.
- Scrapy : un framework complet pour des projets de scraping plus complexes.
➡ Pour Node.js :
- Axios ou Fetch : pour envoyer des requêtes HTTP.
- Cheerio : similaire à BeautifulSoup, très efficace pour parcourir et manipuler le DOM.
- Puppeteer ou Playwright : essentiels pour scraper des sites dynamiques qui utilisent beaucoup de JavaScript.
Tutoriel pour créer un bot de web scraping
Créer un bot de web scraping peut sembler complexe. Mais pas d’inquiétude ! En suivant ces étapes, vous aurez un script fonctionnel rapidement.
⚠ Assurez-vous d’avoir installé Python, ainsi que les bibliothèques nécessaires.
Étape 1 : Analyser le site cible
Avant de coder, il faut savoir où se trouvent les données. Pour cela :
-
- Ouvrez le site dans votre navigateur.
- Faites un clic droit, puis sélectionnez “Inspecter” sur l’élément qui vous intéresse.
- Identifiez les balises HTML, les classes ou les ID qui contiennent les données à extraire (Exemple :
.product,.title,.price). - Testez des sélecteurs CSS dans la console (Exemple : si les titres des produits sont dans des balises
<h2 class="title">, utilisez ce sélecteur dans votre code).
Étape 2 : Envoyer une requête HTTP
Votre bot va se comporter comme un navigateur : il envoie une requête HTTP au serveur du site et le serveur renvoie le code HTML.
# pip install requests
import requests
url = "https://exemple.com/produits"
headers = {"User-Agent": "Mozilla/5.0"}
resp = requests.get(url, headers=headers, timeout=15)
resp.raise_for_status() # erreur si code != 200
html = resp.text
print(html[:500]) # aperçuÉtape 3 : Parser le contenu HTML
Maintenant que vous avez récupéré la page, il faut la transformer en un objet manipulable.
C’est le rôle de BeautifulSoup.
# pip install beautifulsoup4
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
produits = soup.select(".product")
print(f"Produits trouvés : {len(produits)}")
for p in produits[:3]:
titre = p.select_one("h2.title").get_text(strip=True)
prix = p.select_one(".price").get_text(strip=True)
lien = p.select_one("a")["href"]
print({"titre": titre, "prix": prix, "lien": lien})Étape 4 : Extraire les données
C’est l’étape la plus intéressante : aller chercher les informations précises comme des titres, des prix, des liens.
from urllib.parse import urljoin
base_url = "https://exemple.com"
data = []
for p in soup.select(".product"):
titre = p.select_one("h2.title").get_text(strip=True)
prix_txt = p.select_one(".price").get_text(strip=True)
lien_rel = p.select_one("a")["href"]
lien_abs = urljoin(base_url, lien_rel)
# normalisation prix
prix = float(prix_txt.replace("€","").replace(",",".").strip())
data.append({"titre": titre, "prix": prix, "url": lien_abs})
print(data[:5])Étape 5 : Sauvegarder les données
Pour ne pas perdre vos résultats, vous pouvez les enregistrer au format CSV ou JSON.
import csv, json, pathlib
pathlib.Path("export").mkdir(exist_ok=True)
# CSV
with open("export/produits.csv", "w", newline="", encoding="utf-8") as f:
champs = ["titre", "prix", "url"]
writer = csv.DictWriter(f, fieldnames=champs, delimiter=";")
writer.writeheader()
writer.writerows(data)
# JSON
with open("export/produits.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print("Export terminé !")Comment contourner les mesures de protection face au web scraping ?
Il faut savoir que les sites mettent en place plusieurs mécanismes pour protéger leurs données. Comprendre ces protections est essentiel pour scraper de manière efficace et responsable.
- robots.txt
📌Le fichier robots.txt indique quelles pages un bot peut ou ne peut pas visiter.
✅ Vérifiez toujours ce fichier avant de scraper un site. Le respecter vous permet d’éviter des actions non autorisées et des problèmes légaux.
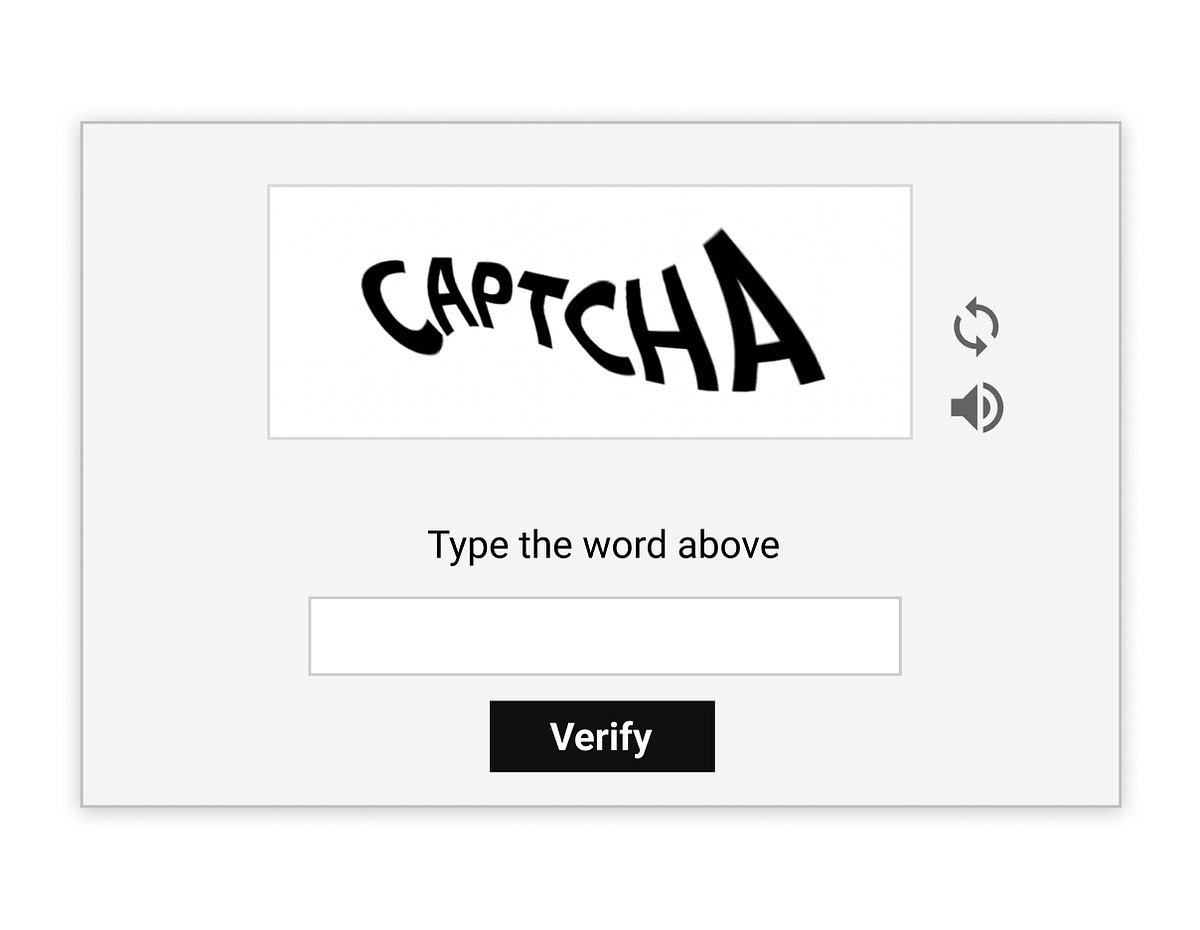
- Captchas
📌 Ils servent à vérifier que l’utilisateur est humain.
✅ Pour les contourner, utilisez des bibliothèques d’automatisation pour simuler un vrai navigateur ou des services tiers spécialisés dans la résolution de captchas.
- Blocages par adresse IP
📌 Certains sites détectent un grand nombre de requêtes venant de la même IP et bloquent l’accès.
✅ Il est donc recommandé d’utiliser des proxies ou un VPN pour changer régulièrement d’adresse IP.
- Blocages par user-agent
📌 Les sites peuvent refuser les requêtes venant de bots identifiés par des User-Agent suspects.
✅ L’astuce est de définir un User-Agent réaliste dans vos requêtes HTTP pour simuler un navigateur classique.
- Sites JavaScript
📌 Certaines pages chargent leur contenu via JavaScript, ce qui empêche les simples requêtes HTTP de récupérer les données.
✅ Pour les contourner, vous pouvez utiliser des outils comme Selenium, Playwright ou Puppeteer.
FAQ
Quelle est la différence entre un bot de web scraping et un crawler web ?
| Web scraping | Crawler web |
|---|---|
| Se concentre sur des données spécifiques : titres, prix, liens des produits, etc. Le bot lit le HTML, identifie les éléments pertinents et les extraits pour les utiliser ensuite (analyse, stockage, export, etc.) |
C’est un programme qui parcourt automatiquement des pages web en suivant les liens afin de découvrir du contenu. Son objectif principal est de parcourir le web pour cartographier et indexer des informations, mais pas nécessairement d’en extraire des données précises. |
Le web scraping est-il légal ?
La légalité du web scraping varie selon le site web, le type de données collectées et l’usage que l’on en fait.
Quels types de données peut-on extraire avec un bot de web scraping ?
Avec un bot de web scraping, vous pouvez collecter :
- 🔥 Des titres et des descriptions de produits.
- 🔥 Des prix et des promotions.
- 🔥 Des liens internes ou externes.
- 🔥 Des avis et des notes d’utilisateurs.
- 🔥 Des informations de contact.
- 🔥 Des contenus textuels ou des images de pages web.
Comment un site web peut-il détecter mon bot de scraping ?
Les sites détectent souvent les bots grâce à des comportements anormaux comme :
- ❌ la vitesse de requête trop élevée ou régulière
- ❌ l’user-agent non standard
- ❌ l’absence de chargement de ressources JavaScript nécessaires
- ❌ la navigation sans cookies, etc.
Quels sont les défis courants lors de la création d’un bot de web scraping ?
Créer un bot efficace n’est pas toujours simple. Parmi les défis fréquents, on cite :
- 🎯 les structures HTML inconsistantes.
- 🎯 les données non structurées.
- 🎯 les problèmes de lenteur de chargement des pages.
Y a-t-il des services ou des APIs de web scraping ?
Oui ! Il existe des services qui simplifient le scraping et qui gèrent des aspects comme les proxies, les captchas ou les sites dynamiques.
Vous pouvez également utiliser des API de web scraping pour accéder à des données structurées. Bright Data est l’une des solutions les plus complètes.
💬 Bref, le web scraping ouvre de nombreuses possibilités pour exploiter les données du web. Créer un bot de web scraping vous permet d’automatiser la collecte de données.




