AWS 彻底简化网页抓取。您无需再处理服务器或崩溃的脚本。
一切都在自动化 您可以轻松处理大量数据。

AWS在网页抓取中扮演什么角色?
这 网络搜刮 允许 自动获取数据 在网站上进行分析或再利用。
⚠ 但要注意,这并非总是易事。管理数百万页面、避免卡顿并确保可靠性,很快就会变成真正的难题。
✅ 就在那里AWS (亚马逊网络服务)介入。该平台 亚马逊云 简化网页抓取 自动化服务器管理通过克服技术挑战,它还确保即使面对海量数据,系统也能稳定安全地运行。
以下几点证实了AWS是网络爬虫的理想解决方案:
- 🔥 可扩展性 该平台能够自动扩展负载,无缝处理数百万次请求。
- 🔥 可靠性 AWS托管服务可最大限度降低故障风险,确保持续运行。
- 🔥 成本效益 : 通过按需付费模式,您只需为实际消耗的服务付费。
- 🔥 安全 AWS实施安全措施以保护数据。
AWS有哪些相关服务?
AWS提供一系列服务,可满足各种网络爬虫需求。
- 计算
➡ AWS Lambda:适用于小型任务。
➡ Amazon EC2:适用于耗时或资源密集型进程。

- 贮存
➡ Amazon S3:用于安全存储原始数据、文件或抓取结果。
➡ Amazon DynamoDB:适用于需要快速读写操作的结构化数据。
- 编排
➡ AWS Step Functions:用于管理复杂的工作流。
- 其他服务
➡ Amazon SQS:用于管理请求队列并组织数据处理。
➡ AWS IAM:用于管理访问权限。
如何使用AWS Lambda构建无服务器抓取器?
和 AWS Lambda您无需管理服务器。AWS负责管理所有基础设施(可扩展性、可用性、维护)。您只需提供代码和配置即可。
请按照以下教程构建一个 使用AWS Lambda实现无服务器爬虫.
1. 无服务器抓取器的基本架构
首先,需要设想不同AWS服务将如何协同工作。
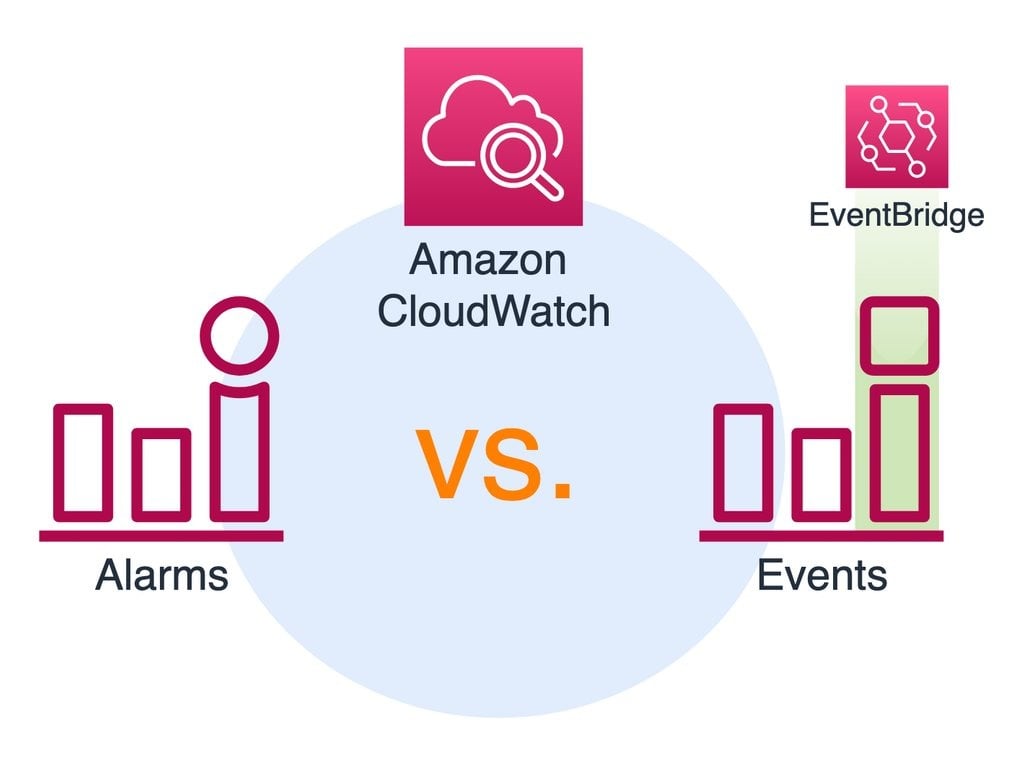
- 选择触发器
这是决定代码何时执行的关键要素。您拥有 CloudWatch 和 EventBridge.
- 选择计算
这是您的代码在云端运行的位置。 拉姆达 对于短暂且不定期的任务, EC2/Fargate 如果工作时间长或工作量大。
- 选择存储
这是您的抓取工具存放结果的存储空间。 S3 对于 JSON/CSV/原始文件, DynamoDB 如果您需要快速且结构化的访问。
✅ 总的来说,触发器激活 Lambda,Lambda 执行抓取操作,数据存储在 S3 中。
2. 环境准备
在编码之前,必须向AWS授予权限并分配存储空间。
- 创建IAM角色(权限)
- 进入控制台 AWS > IAM > 角色.
- 创建一个专用于 Lambda 的角色。
- 授予其两项关键权限:
AWS Lambda 基本执行角色将日志发送到CloudWatch,并授予S3权限以将文件写入您的存储桶。
- 创建S3存储桶(结果存储)
- 进入控制台 AWS > S3.
- 创建一个存储桶。
- 请保持安全设置处于激活状态。
✅ 通过以上操作,您已授予Lambda在S3中写入数据的权限,并为数据存储提供了存放位置。
3. AWS Lambda 的 Python 代码
现在,你可以写一个小 Python中的网页抓取使用像Requests这样简单的库。该脚本将抓取一个页面并将结果存储在S3中。
- 简单代码示例(使用requests):
import json import boto3 import requests import os from datetime import datetime s3_client = boto3.client('s3') def lambda_handler(event, context): # 待抓取URL (此处为简单示例) url = "https://example.com" response = requests.get(url) # 状态验证 if response.status_code == 200: # 文件名(带时间戳以避免冲突)
filename = f"scraping_{datetime.utcnow().isoformat()}.html" # 发送到 S3 s3_client.put_object( Bucket=os.environ['BUCKET_NAME'], # 在您的 Lambda 环境变量中定义
Key=filename, Body=response.text, ContentType="text/html" ) return { 'statusCode': 200, 'body': json.dumps(f"页面已保存至 {filename}")
} else: return { 'statusCode': response.status_code, 'body': json.dumps("抓取时出错") }➡ 要求 允许获取网页内容。
➡ boto3 是与AWS通信的官方库
- 依赖项管理(请求或Scrapy)
Lambda默认不提供requests或Scrapy,因此您有两种选择:
👉 创建ZIP包
- 在您的计算机上创建一个文件夹:
mkdir package && cd packagepip install requests -t .- 添加您的文件
lambda_function.py在此文件中。 - 压缩所有内容
.zip并将它上传到Lambda中。
👉 使用Lambda Layers
- 您创建一个包含Requests(或Scrapy,如果您需要更高级的抓取功能)的Lambda层。
- 您将此层附加到您的Lambda函数上。
优势 :在多个函数中复用相同的依赖项会更整洁。
4. 部署与测试
接下来只需将您的代码发布到线上,并验证其运行状态。
- 将代码上传至Lambda
- 登录到 AWS 控制台 然后进入Lambda服务。
- 点击 创建函数然后选择 作者从零开始.
- 为您的函数命名(例如:
scraper-lambda)并选择 Python 3.12 运行时 (或您使用的版本)。 - 将您创建的IAM角色与S3 + CloudWatch权限关联起来。
- 在 编码选择 上传自, 然后
.zip文件并导入您的文件lambda_package.zip(包含您的代码和依赖项的那个,例如要求). - 添加一个环境变量:
BUCKET_NAME= 您的 S3 存储桶名称。 - 点击 保存 以保护您的职位。
- 测试功能
- 在您的Lambda函数中,点击 测试.
- 创建一个包含小型 JSON 的新测试事件,例如:
{ "url": "https://example.com" }- 点击 保存然后 测试 执行该功能。
- 在 日志请检查状态:如果一切正常,您应该看到代码200。
- 进入您的S3存储桶:您应该会看到一个文件出现。
scraping_xxxx.html.
大规模网络爬虫有哪些解决方案?
要收集数百万页内容,需要强大的基础设施。AWS提供多种工具,特别是用于扩展能力的工具。
1. 使用 Scrapy 和 AWS Fargate/EC2

废料 非常适合复杂项目。它使您能够编写您的抓取代码但默认情况下,您的抓取程序在您的计算机上运行,这很快就会受到限制。
AWS Fargate 然后允许您在 Docker容器 无需管理服务器。这是实现自动扩展的关键。
亚马逊弹性计算云(Amazon EC2) 这也是一个选择,如果你希望对你的环境有更多控制权。
✅ 总的来说,要将Scrapy爬虫容器化:
- ✔ 您创建自己的Scrapy抓取器。
- ✔ 将其放入Docker容器中。
- ✔ 您使用Fargate部署此容器,使其能够自动大规模运行。
2. 分布式抓取架构
您可以使用 亚马逊SQS (简单队列服务)。它用于管理待抓取URL的队列。您只需将所有URL放入SQS,然后使用多个Lambda函数或多个容器(在EC2或Fargate上)即可。 并行获取这些URL 启动抓取。
这样您就可以 分工 同时前进。
3. 管理代理和被阻止的请求
需要注意的是,许多网站会通过检测过多的请求或过滤某些IP地址来阻止爬虫程序。
解决方案如下:
- 这 IP地址轮换 通过AWS或专业服务。
- 使用 第三方代理 作为 亮数据 在哪里 ScrapingBee 自动管理轮换和防抱死功能。

AMS如何解决网络爬虫的常见问题?
在网络爬虫领域,障碍总是如影随形:网络错误、封锁、意外成本等等。值得庆幸的是,AWS已提供工具可快速诊断并解决这些问题。
使用 Amazon CloudWatch 分析日志
当Lambda函数或EC2实例发生故障时,若缺乏可见性,则难以确定错误的来源。
✅ 基于 Amazon CloudWatch 的解决方案 所有日志均集中存储且可供查阅。您可从中识别常见错误,例如:
- Timeouts (请求耗时过长)。
- 错误 403 Forbidden (该网站阻止了您的爬虫程序)。
- 错误 429 Too Many Requests (发送请求过多)。
- Lambda 中内存不足或缺少依赖项。
💡 配置 CloudWatch警报 当某个错误频繁出现时,自动收到通知。
查询错误管理
如果单个请求失败,刮取器可能会完全崩溃。
✅ 使用错误处理 用Python实现 try...except这可防止程序突然停止运行。
✅ 重试策略 (重试):
- 稍后重试,然后逐步延长等待时间(指数级后退)。
- 如果某个IP被封锁,则在多个代理之间切换。
- 调整请求频率以规避检测。
成本跟踪
优化不当的爬虫可能触发数千次Lambda调用,或导致大型EC2实例无谓运行,从而产生远超预期的成本。
✅ 基于AWS计费的解决方案 监控每个服务(Lambda、EC2、S3、代理服务器)的资源消耗情况。
✅ 优化建议 :
- 对于Lambda:减少内存或限制运行时间。
- 对于EC2:选择合适的实例或使用竞价实例(价格更低,但可能随时中断)。
- 启用AWS预算警报,在超出阈值前收到通知。
常见问题
使用AWS进行网络爬虫是否合法?
这要看情况。
这 网络搜索的合法性 根据国家、收集的数据以及您对数据的使用情况而有所不同。某些网站在其条款中也禁止抓取行为。
使用AWS进行网络爬虫的最佳方法是什么?
这完全取决于您的项目:
- AWS Lambda :适用于小型快速刮板。
- EC2 :适用于更复杂的项目。
- Fargate 用于分布式抓取。
我可以在AWS Lambda上使用Selenium进行网页抓取吗?
👉 是的,但情况更复杂。
硒 或其他 无头浏览器 像Puppeteer这样的工具对于实现 JavaScript中的网页抓取然而,在Lambda上的配置需要进行优化(包大小、依赖管理)。
如何避免被AWS上的网站封禁?
网站能够检测到爬虫并阻止请求。以下是一些常见的降低风险的策略:
- ✔ 定期修改用户代理.
- ✔ 添加随机延迟 在请求之间。
- ✔ 使用轮换代理.
- ✔ 避免发送过多请求 同时从同一IP地址。
如何将抓取的数据整合到数据库中?
数据收集完成后,您可以将其插入关系型数据库,例如 亚马逊关系型数据库服务 (MySQL、PostgreSQL等)。
最佳实践是 清理和结构化数据 插入前,然后自动化集成 通过Python脚本或管道实现。这确保了基础架构的整洁且可立即投入使用。
👌 简而言之,通过结合AWS 和 网页抓取的最佳实践您可以高效且安全地提取数据。欢迎在评论区分享您的使用体验!





